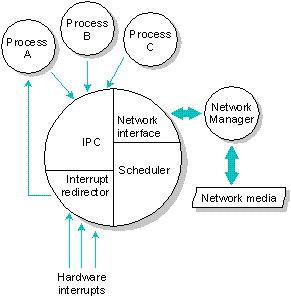
The QNX Microkernel supports three essential types of
interprocess communication: messages, proxies, and signals.
In QNX, a message is a packet of bytes that's synchronously
transmitted from one process to another. QNX attaches no
meaning to the content of a message. The data in a message
has meaning for the sender and for the recipient, but for no
one else.
To communicate directly with one another, cooperating processes use
these C language functions:
| C Function: | Purpose: |
|---|
| Send() | to send messages |
| Receive() | to receive messages |
| Reply() | to reply to processes that have sent messages |
These functions may be used locally or across the network.
Note also that unless processes want to communicate directly
with each other, they don't need to use Send(),
Receive(), and Reply(). The QNX C
Library is built on top of messaging — processes use
messaging indirectly when they use standard services, such
as pipes.
Process A sends a message to Process B, which subsequently
receives, processes, then replies to the message.
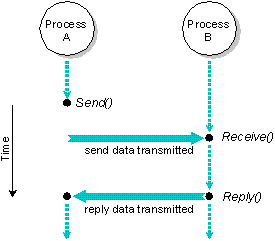
The above illustration outlines a simple sequence of events
in which two processes, Process A and Process B,
use Send(), Receive(), and
Reply() to communicate with each other:
- Process A sends a message to Process B by
issuing a Send() request to the Microkernel. At
this point, Process A becomes SEND-blocked until
Process B issues a Receive() to receive the
message.
- Process B issues a Receive() and
receives Process A's waiting message. Process A
changes to a REPLY-blocked state. Since a message was
waiting, Process B doesn't block.
(Note that if Process B had issued the
Receive() before a message was sent, it would
become RECEIVE-blocked until a message arrived. In this
case, the sender would immediately go into the REPLY-blocked
state when it sent its message.)
- Process B completes the processing associated with
the message it received from Process A and issues a Reply().
The reply message is copied to Process A, which is made ready to
run. A Reply() doesn't block, so Process B is also ready
to run. Who runs depends on the relative priorities of Process A
and Process B.
Message passing not only allows processes to pass data to
each other, but also provides a means of synchronizing the
execution of several cooperating processes.
Let's look at the above illustration again. Once
Process A issues a Send() request, it's
unable to resume execution until it has received the reply
to the message it sent. This ensures that the processing
performed by Process B for Process A is complete
before Process A can resume executing. Moreover, once
Process B has issued its Receive() request,
it can't continue processing until it receives another
message.
For details on how QNX schedules processes, see
“Process
scheduling” in this chapter.
When a process isn't allowed to continue executing —
because it must wait for some part of the message protocol
to end — the process is said to be blocked.
The following table summarizes the blocked states of processes:
| If a process has issued a: | The process is: |
|---|
| Send() request, and the message it has sent
hasn't yet been received by the recipient process | SEND-blocked |
| Send() request, and the message has been
received by the recipient process, but that process hasn't
yet replied | REPLY-blocked |
| Receive() request, but hasn't yet received a
message | RECEIVE-blocked |
A process undergoing state changes in a typical send-receive-reply transaction.
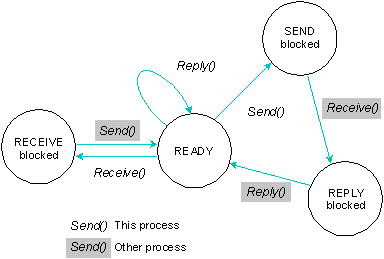 For information on all possible process states, see Chapter
3, “The Process
Manager.”
For information on all possible process states, see Chapter
3, “The Process
Manager.”
Let's now take a closer look at the Send(),
Receive(), and Reply() function calls.
We'll stay with our example of Process A and
Process B.
Let's assume Process A issues a request to send a
message to Process B. It issues the request by means of
a Send() function call:
Send( pid, smsg, rmsg, smsg_len, rmsg_len );
The Send() call contains these arguments:
- pid
- the process ID of the process that is
to receive the message (i.e. Process B); a pid
is the identifier by which the process is known to the
operating system and to other processes
- smsg
- the message buffer (i.e. the message to be sent)
- rmsg
- the reply buffer (will contain the reply from
Process B)
- smsg_len
- the length of the message being sent
- rmsg_len
- the maximum length of the reply that Process A will
accept
Note that no more than smsg_len bytes will be
sent, and no more than rmsg_len bytes will be
accepted in the reply — this ensures that buffers
aren't accidentally overwritten.
Process B can receive the Send() issued from Process A
by issuing a Receive() call:
pid = Receive( 0, msg, msg_len );
The Receive() call contains these arguments:
- pid
- the process ID of the process that sent the message
(i.e. Process A) is returned
- 0
- (zero) specifies that Process B is willing to
accept a message from any process
- msg
- the buffer where the message will be received
- msg_len
- the maximum amount of data that will be accepted in the
receive buffer
If the smsg_lenin the Send() call and
the msg_len in the Receive() call
differ in size, the smaller of the two determines the amount
of data that will be transferred.
Having successfully received the message from
Process A, Process B should reply to
Process A by issuing a Reply() function
call:
Reply( pid, reply, reply_len );
The Reply() call contains these arguments:
- pid
- the process ID of the process to which the reply
is directed (i.e. Process A)
- reply
- the reply buffer
- reply_len
- the length of the data to be transmitted in the reply
If the reply_lenin the Reply() call
and the rmsg_len in the Send() call
differ in size, the smaller of the two determines how much
data will be transferred.
The messaging example we just looked at illustrates the most
common use of messaging — that in which a server
process is normally RECEIVE-blocked for a request from a
client in order to perform some task. This is called
send-driven messaging: the client process initiates
the action by sending a message, and the action is finished
by the server replying to the message.
Although not as common as send-driven messaging, another
form of messaging is also possible — and often
desirable — to use: reply-driven messaging,
in which the action is initiated with a Reply()
instead. Under this method, a “worker” process
sends a message to the server indicating that it's available
for work. The server doesn't reply immediately, but rather
“remembers” that the worker has sent an arming
message. At some future time, the server may decide to
initiate some action by replying to the available worker
process. The worker process will do the work, then finish
the action by sending a message containing the results to
the server.
Here are some more things to keep in mind about message
passing:
- The message data is maintained in the sending process
until the receiver is ready to process the message. There is
nocopying of the message into the Microkernel. This
is safe since the sending process is SEND-blocked and is
unable to inadvertently modify the message data.
- The message reply data is copied from the replying
process to the REPLY-blocked process as an atomic operation
when the Reply() request is issued. The
Reply() doesn't block the replying process
— the REPLY-blocked process becomes unblocked after
the data is copied into its space.
- The sending process doesn't need to know anything about
the state of the receiving process before sending a message.
If the receiving process isn't prepared to receive a message
when the sending process issues it, the sending process
simply becomes SEND-blocked.
- If necessary, a process can send a zero-length message,
a zero-length reply, or both.
- From the developer's point of view, issuing a
Send() to a server process to get a service is
virtually identical to calling a library subroutine to get
the same service. In either case, you set up some data
structures, then make the Send() or the library
call. All of the service code between two well-defined
points — Receive() and Reply()
for a server process, function entry and return
statement for a library call — then executes while
your code waits. When the service call returns, your code
“knows” where results are stored and can proceed
to check for error conditions, process results, or whatever.
Despite this apparent simplicity, the code does much more
than a simple library call. The Send() may
transparently go across the network to another machine where
the service code actually executes. It can also exploit
parallel processing without the overhead of creating a new
process. The server process can issue a Reply(),
allowing the caller to resume execution as soon as it is
safe to do so, and meanwhile continue its own execution.
- There may be messages outstanding from many processes
for a single receiving process. Normally, the receiving
process receives the messages in the order they were sent by
other processes; however, the receiving process can specify
that messages be received in an order based on the priority
of the sending processes.
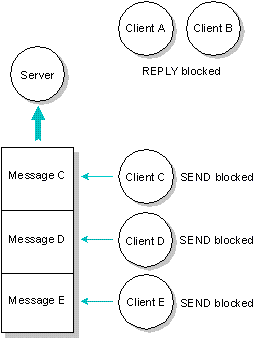
Server has received (but not replied to) messages from
Client A and Client B. Server has not yet received messages
from Client C, Client D, and Client E.
QNX also provides these advanced message-passing facilities:
- conditional message reception
- reading or writing part of a message
- multipart messages
Generally, when a process wants to receive messages, it uses
Receive() to wait for a message to arrive. This
is the normal way of receiving messages and is appropriate
in most circumstances.
In some cases, however, a process may need to determine
whether messages are pending, yet may not want to become
RECEIVE-blocked in the absence of a pending message. For
example, a process needs to poll a free-running device at
high speed — the device isn't capable of generating
interrupts — but the process still has to respond to
messages from other processes. In this case, the process
could use the Creceive() function to read a
message, if one became available, yet return immediately if
no further messages were pending.
You should avoid Creceive(), if possible, since
it allows a process to consume the processor continuously at
its priority level.
Sometimes it's desirable to read or write only part of a
message at a time so that you can use the buffer space
already allocated for the message instead of allocating a
separate work buffer.
For example, an I/O manager may accept messages of data to
be written that consist of a fixed-size header followed by a
variable amount of data. The header contains the byte count
of the data (0 to 64K bytes). The I/O manager may elect to
receive only the header and then use the
Readmsg() function to read the variable-length
data directly into an appropriate output buffer. If the sent
data exceeds the size of the I/O manager's buffer, the
manager may issue several Readmsg() requests over
time to transfer the data as space becomes available.
Likewise, the Writemsg() function can be used to
collect data over time and copy it back to the sender's
reply buffer as it becomes available, thus reducing the I/O
manager's internal buffer requirements.
Up to now, messages have been discussed as single packets of
bytes. However, messages often consist of two or more
discrete components. For example, a message may have a
fixed-length header followed by a variable amount of data.
To ensure that its components will be efficiently sent or
received without being copied into a temporary work buffer,
a multipart message can be constructed from two or more
separate message buffers. This facility helps QNX I/O
managers, such as Dev and Fsys,
achieve their high performance.
The following functions are available to handle multipart
messages:
- Creceivemx()
- Readmsgmx()
- Receivemx()
- Replymx()
- Sendmx()
- Writemsgmx()
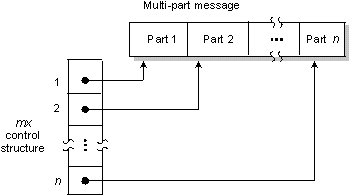
Multipart messages can be specified with an mx
control structure. The Microkernel assembles these into a
single data stream.
Although you aren't required to do so, QNX begins all of its
messages with a 16-bit word called a message code.
Note that QNX system processes use message codes in the
following ranges:
| Reserved range: | Description: |
|---|
| 0x0000 to 0x00FF | Process Manager messages |
| 0x0100 to 0x01FF | I/O messages (common to all I/O servers) |
| 0x0200 to 0x02FF | Filesystem Manager messages |
| 0x0300 to 0x03FF | Device Manager messages |
| 0x0400 to 0x04FF | Network Manager messages |
| 0x0500 to 0x0FFF | Reserved for future QNX system processes |
A proxy is a form of non-blocking message
especially suited for event notification where the sending
process doesn't need to interact with the recipient. The
only function of a proxy is to send a fixed message to a
specific process that owns the proxy. Like messages,
proxies work across the network.
By using a proxy, a process or an interrupt handler can send
a message to another process without blocking or having to
wait for a reply.
Here are some examples of when proxies are used:
- A process wants to notify another process that an event
has occurred, but can't afford to become SEND-blocked until
the recipient issues a Receive() and a
Reply().
- A process wants to send data to another process, but
needs neither a reply nor any other acknowledgment that the
recipient has received the message.
- An interrupt handler wants to tell a process that some
data is available for processing.
Proxies are created with the qnx_proxy_attach()
function. Any other process or any interrupt handler that
knows the identification of the proxy can then cause the
proxy to deliver its predefined message by using the
Trigger() function. The Microkernel handles the
Trigger() request.
A proxy can be triggered more than once — it sends a
message for each time it's triggered. A proxy process can
queue up to 65,535 messages for delivery.
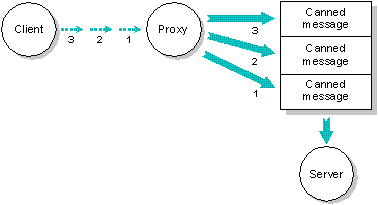
A client process triggers a proxy three times, which causes
the server to receive three “canned” messages
from the proxy.
Signals are a traditional method of asynchronous communication that
have been available for many years in a variety of operating systems.
QNX supports a rich set of POSIX-compliant signals, some
historical UNIX signals, as well as some QNX-specific
signals.
A signal is considered to have been delivered to a process
when the process-defined action for that signal is taken. A
process can set a signal on itself.
| If you want to: | Use the: |
|---|
| Generate a signal from the shell | kill or slay utilities |
| Generate a signal from within a process | kill() or raise() C functions |
A process can receive a signal in one of three ways,
depending on how it has defined its signal-handling
environment:
- If the process has taken no special action to handle
signals, the default action for the signal is taken —
usually, this default action is to terminate the process.
- The process can ignore the signal. If a process ignores
a signal, there's no effect on the process when the signal
is delivered (note that the SIGCONT, SIGKILL, and SIGSTOP
signals can't be ignored under normal circumstances).
- The process can provide a signal handler for
the signal — a signal handler is a function in the
process that is invoked when the signal is delivered. When a
process contains a signal handler for a signal, it is said
to be able to “catch” the signal. Any process
that catches a signal is, in effect, receiving a form of
software interrupt. No data is transferred with the signal.
Between the time that a signal is generated and the time
that it's delivered, the signal is said to be pending.
Several distinct signals can be pending for a process at a
given time. Signals are delivered to a process when the
process is made ready to run by the Microkernel's scheduler.
A process should make no assumptions about the order in
which pending signals are delivered.
Signals are listed here in several tables:
- standard signals
- job control signals
- QNX-specific signals
- historical UNIX signals
The default action for all of the following signals is to
terminate the process. Note that except for SIGKILL, all can
be caught or ignored.
| Signal: | Description: |
|---|
| SIGABRT | Abnormal termination signal such as issued by the
abort() function. |
| SIGALRM | Timeout signal such as issued by the alarm()
function. |
| SIGFPE | Erroneous arithmetic operation (integer or floating
point), such as division by zero or an operation resulting
in overflow. Note that if a second fault occurs while your
process is in a signal handler for this fault, the process
will be terminated. |
| SIGHUP | Death of session leader, or hangup detected on
controlling terminal. |
| SIGILL | Detection of an invalid hardware instruction. Note that
if a second fault occurs while your process is in a signal
handler for this fault, the process will be terminated. |
| SIGINT | Interactive attention signal (Break) |
| SIGKILL | Termination signal — should be used only for
emergency situations. This signal cannot be caught or
ignored. Note that a server with superuser privileges
may protect itself from this signal via the
qnx_pflags() function. |
| SIGPIPE | Attempt to write on a pipe with no readers. |
| SIGQUIT | Interactive termination signal. |
| SIGSEGV | Detection of an invalid memory reference. Note that if a
second fault occurs while your process is in a signal
handler for this fault, the process will be terminated. |
| SIGTERM | Termination signal |
| SIGUSR1 | Reserved as application-defined signal 1 |
| SIGUSR2 | Reserved as application-defined signal 2 |
These signals are optional according to POSIX 1003.1. Note
that except for SIGCHLD, none of these job control signals
can be caught or ignored.
| Signal: | Description: |
|---|
| SIGCHLD | Child process terminated. The default action is to
ignore the signal. |
| SIGCONT | Continue if HELD. The default action is to ignore the
signal if the process isn't HELD. |
| SIGSTOP | HOLD process signal. The default action is to hold the
process. Note that a server with superuser privileges may
protect itself from this signal via the
qnx_pflags() function. |
| SIGTSTP | Not supported by QNX. |
| SIGTTIN | Not supported by QNX. |
| SIGTTOU | Not supported by QNX. |
All these QNX-specific signals can be caught or ignored. The
default action for all of them is to terminate the process.
| Signal: | Description: |
|---|
| SIGBUS | Indicates a memory parity error (QNX-specific
interpretation). Note that if a second fault occurs while
your process is in a signal handler for this fault, the
process will be terminated. |
| SIGDEV | Generated when a significant and requested event occurs
in the Device Manager |
| SIGPWR | Soft boot requested via
Ctrl-Alt-Shift-Del or shutdown utility. |
All of these signals can be caught or ignored. The default
action for all of them is to terminate the process.
Note these signals are defined for historical compatibility
with some UNIX systems; they are not generated by
any QNX component.
| Signal: | Description: |
|---|
| SIGIOT | IOT instruction |
| SIGSYS | Bad argument to system call |
| SIGWINCH | Window change |
| SIGURG | Urgent condition present on socket |
| SIGPOLL | Pollable event occurred |
| SIGEMTM | EMT instruction (emulator trap) |
| SIGTRAP | Unsupported software interrupt |
To define the type of handling you want for each signal, you
use the ANSI C signal() function or the POSIX
sigaction() function.
The sigaction() function gives you greater
control over the signal-handling environment.
You may change the type of handling for a signal at any
time. If you set the signal handling for a function to
ignore the signal, any pending signals of that type will be
immediately discarded.
Some special considerations apply to processes that catch signals
with a signal-handling function.
The signal-handling function is similar to a software
interrupt. It is executed asynchronously to the rest of the
process. Therefore, it's possible for a signal handler to be
entered while any function in the program is running
(including library functions).
If your process doesn't return from the signal handler, it
can use either siglongjmp() or
longjmp(), but siglongjmp() is
preferred. With longjmp(), the signal remains
blocked.
The POSIX and ANSI C library functions listed below are
specified as being safe to use within signal handlers. You
shouldn't try to use any other library functions, since the
results of doing so are unspecified and unpredictable. Nor
should you try to use any user functions in your program
unless they are re-entrant.
_exit()
access()
alarm()
cfgetispeed()
cfgetospeed()
cfsetispeed()
cfsetospeed()
chdir()
chmod()
chown()
close()
creat()
dup2()
dup()
execle()
execve()
fcntl()
fork()
fstat()
getegid()
geteuid()
getgid()
getgroups()
getpgrp()
getpid()
getppid()
getuid()
kill()
link()
lseek()
mkdir()
mkfifo()
open()
pathconf()
pause()
pipe()
read()
rename()
rmdir()
setgid()
setpgid()
setsid()
setuid()
sigaction()
sigaddset()
sigdelset()
sigemptyset()
sigfillset()
sigismember()
signal()
sigpending()
sigprocmask()
sigsuspend()
sleep()
stat()
sysconf()
tcdrain()
tcflow()
tcflush()
tcgetattr()
tcgetpgrp()
tscendbreak()
tcsetattr()
tcsetgrp()
time()
times()
umask()
uname()
unlink()
ustat()
utime()
wait()
waitpid()
write()
Sometimes you may want to temporarily prevent a signal from
being delivered, without changing the method of how the
signal is handled when it is delivered. QNX provides a set
of functions that let you block delivery of signals. A
signal that is blocked remains pending; once unblocked, it
is delivered to your program.
While your process is executing a signal handler for a
particular signal, QNX automatically blocks that signal.
This means that you don't have to worry about setting up
nested invocations of your handler. Each invocation of your
signal handler is an atomic operation with respect to the
delivery of further signals of that type. If your process
returns normally from the handler, the signal is
automatically unblocked.
Some UNIX systems have a flawed implementation of signal
handlers in that they reset the signal to the default action
rather than block the signal. As a result, some UNIX
applications call the signal() function within
the signal handler to re-arm the handler. This has two
windows of failure. First, if another signal arrives while
your program is in the handler but before
signal() is called, your program may be killed.
Second, if a signal arrives just after the call to
signal() in the handler, you might enter your
handler recursively. QNX supports signal blocking and
therefore avoids these problems. You don't need to call
signal() within your handler. If you leave your
handler via a long jump, you should use the
siglongjmp() function.
There's an important interaction between signals and messages. If
your process is SEND-blocked or RECEIVE-blocked when a
signal is generated — and you have a signal handler
— the following actions occur:
- The process is unblocked.
- Signal-handling processing takes place
- The Send() or Receive() returns with an error
If your process was SEND-blocked at the time, this doesn't
represent a problem, because the recipient wouldn't have
received a message. But if your process was REPLY-blocked,
you won't know whether the sent message had been handled or
not, and therefore won't know whether to retry the
Send().
It's possible for a process acting as a server (i.e. it is
receiving messages) to ask that it be notified when a client
process is signaled while in the REPLY-blocked state. In
this case, the client process is made SIGNAL-blocked with a
pending signal and the server process receives a special
message describing the type of signal. The server process
can then decide to do either of the following:
- Complete the original request normally — the sender is
assured that the message was handled properly.
OR
- Release any resources tied up and return an error
indicating that the process was unblocked by a signal
— the sender receives a clear-error indication.
When the server replies to a process that was
SIGNAL-blocked, the signal will take effect immediately
after the sender's Send() returns.
A QNX application can talk to a process on another computer
on the network just as if it were talking to another process
on the same machine. As a matter of fact, from the
application's perspective, there's no difference between a
local and remote resource.
This remarkable degree of transparency is made possible by
virtual circuits (VCs), which are paths the Network
Manager provides to transmit messages, proxies, and signals
across the network.
VCs contribute to efficient overall use of resources in a
QNX network for several reasons:
- When a VC is created, it's given the ability to handle
messages up to a specified size; this means you can
preallocate resources to handle the message. Nevertheless,
if you need to send a message larger than the maximum
specified size, the VC is automatically resized to
accommodate the larger message.
- If two processes residing on different nodes are
communicating with each other via more than one VC, the VCs
are shared — only one real virtual circuit
exists between the processes. This situation occurs commonly
when a process accesses several files on a remote
filesystem.
- If a process attaches to an existing shared VC and it
requests a buffer size larger than that currently in use,
the buffer size is automatically increased.
- When a process terminates, its associated VCs are
automatically released.
A sending process is responsible for setting up the VC
between itself and the process it wants to communicate with.
To do so, the sending process usually issues a
qnx_vc_attach() function call. In addition to
creating a VC, this call also creates a virtual process ID,
or VID, at each end of the circuit. To the process at either
end of the virtual circuit, the VID on its end appears to
have the process ID of the remote process it wants to
communicate with. Processes communicate with each other via
these VIDs.
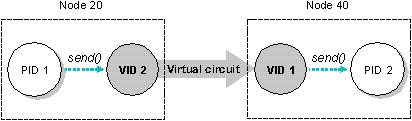
For example, in the following illustration, a virtual
circuit connects PID 1 to PID 2. On node 20
— where PID 1 resides — a VID represents
PID 2. On node 40 — where PID 2 resides
— a VID represents PID 1. Both PID 1 and
PID 2 can refer to the VID on their node as if it were
any other local process (sending messages, receiving
messages, raising signals, waiting, etc.). So, for example,
PID 1 can send a message to the VID on its end, and
this VID will relay the message across the network to the
VID representing PID 1 on the other end. This VID will
then route the message to PID 2.
Network communications is handled with virtual circuits.
When PID 1 sends to VID 2, the send request is relayed
across the virtual circuit causing VID 1 to send to PID 2.
Each VID maintains a connection that contains the following
information:
- local pid
- remote pid
- remote nid (node ID)
- remote vid
You probably won't come into direct contact with VCs very
often. For example, when an application wants to access an
I/O resource across the network, a VC is created by the
open() library function on the application's
behalf. The application has no direct part in the creation
or use of the VC. Again, when an application establishes the
location of a server with qnx_name_locate(), a VC
is automatically created on behalf of the application. To
the application, the VC simply appears to be a PID.
For more information on qnx_name_locate(), see
the discussion of process symbolic
names in Chapter 3.
A process might become unable to communicate over an
established VC for various reasons:
- The computer it was running on was powered down.
- The network cable to the computer was disconnected.
- The remote process it was communicating with was terminated.
Any of these conditions can prevent messages from being transmitted
over a VC. It's necessary to detect these situations so that
applications can take remedial action or terminate themselves gracefully.
If this isn't done, valuable resources can be unnecessarily tied up.
The Process Manager on each node checks the integrity of the VCs
on its node. It does this as follows:
- Each time a successful transmission takes place on a
VC, a time stamp associated with the VC is updated to
indicate the time of last activity.
- At installation-defined intervals, the Process Manager
looks at each VC. If there's been no activity on a circuit,
the Process Manager sends a network integrity packet to the
Process Manager on the node at the other end of the circuit.
- If no response comes back, or if a problem is indicated,
the VC is flagged as having a problem. An
installation-defined number of attempts are then made to
re-establish contact.
- If the attempts fail, the VC is dismantled; any process
blocked on the VC is made READY. (The process sees a failure
return code from the communication primitive on the VC.)
To control parameters related to this integrity check, you use the
netpoll utility.
The Microkernel's scheduler makes scheduling decisions when:
- a process becomes unblocked
- the timeslice for a running process expires
- a running process is preempted
In QNX, every process is assigned a priority. The scheduler
selects the next process to run by looking at the priority
assigned to every process that is READY (a READY process is
one capable of using the CPU). The process with the highest
priority is selected to run.
The ready queue for six processes (A-F) which are READY.
All other processes (G-Z) are BLOCKED. Process A is
currently running. Processes A, B, and C are at the highest
priority, so will share the processor based on the running
process's scheduling algorithm.
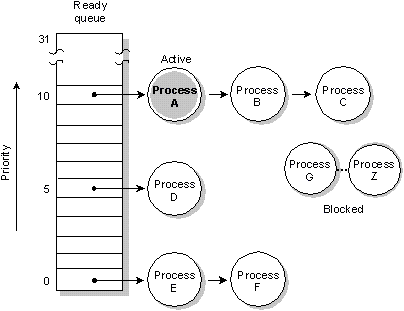
The priorities assigned to processes range from 0 (the
lowest) to 31 (the highest). The default priority for a new
process is inherited from its parent; this is normally set
to 10 for applications started by the Shell.
| If you want to: | Use this function: |
|---|
| Determine the priority of a process | getprio() |
| Set the priority of a process | setprio() |
To meet the needs of various applications, QNX provides
three scheduling methods:
- FIFO scheduling
- round-robin scheduling
- adaptive scheduling
Each process on the system may run using any one of these
methods. They are effective on a per-process basis, not on a
global basis for all processes on a node.
Remember that these scheduling methods apply only when two
or more processes that share the same priority are READY
(i.e. the processes are directly competing with each other).
If a higher-priority process becomes READY, it immediately
preempts all lower-priority processes.
In the following diagram, three processes of equal priority
are READY. If Process A blocks, Process B will
run.
Process A blocks, Process B runs.
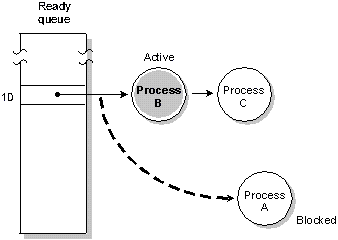
Although a process inherits its scheduling method from its
parent process, you can change the method.
| If you want to: | Use this function: |
|---|
| Determine the scheduling method for a process | getscheduler() |
| Set the scheduling method for a process | setscheduler() |
In FIFO scheduling, a process selected to run continues
executing until it:
- voluntarily relinquishes control (e.g. it blocks)
- is preempted by a higher-priority process
FIFO scheduling. Process A runs until it blocks.
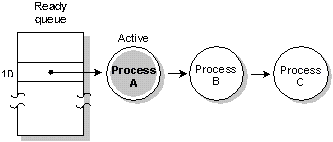
Two processes that run at the same priority can use FIFO
scheduling to ensure mutual exclusion to a shared resource.
Neither process will be preempted by the other while it is
executing. For example, if they shared a memory segment,
each of the two processes could update the segment without
resorting to some form of semaphoring.
In round-robin scheduling, a process selected to run
continues executing until it:
- voluntarily relinquishes control
- is preempted by a higher-priority process
- consumes its timeslice
Round-robin scheduling. Process A ran until it consumed its timeslice; the
next READY process (Process B) now runs.
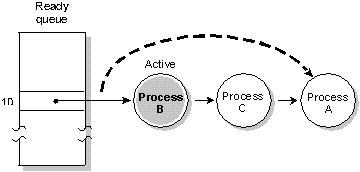
A timeslice is the unit of time assigned to every process.
Once it consumes its timeslice, a process is preempted and
the next READY process at the same priority level is given
control. A timeslice is 100 milliseconds.
Apart from time slicing, round-robin scheduling is identical
to FIFO scheduling.
In adaptive scheduling, a process behaves as follows:
- If the process consumes its timeslice (i.e. it doesn't
block), its priority is reduced by 1 if another process at
the same priority is READY. This is known as priority
decay.
- If the process has decayed and remains unscheduled for one
second, its priority is boosted by 1 (a process is never
boosted above its original priority).
- If the process blocks, it immediately reverts to its
original priority.
Adaptive scheduling. Process A consumed its timeslice; its
priority was then dropped by 1. The next READY process
(Process B) runs.
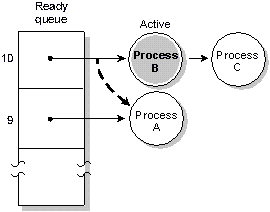
You can use adaptive scheduling in environments where
potentially compute-intensive background processes are
sharing the computer with interactive users. You should find
that adaptive scheduling gives the compute-intensive
processes sufficient access to the CPU, yet retains fast
interactive response for other processes.
Adaptive scheduling is the default scheduling method for
programs created by the Shell.
In QNX, most transactions between processes follow a
client/server model. Servers provide some
form of service and clients send messages to these
servers to request service. In general, servers are more
trusted and vital than clients.
Clients usually outnumber servers. As a result, a server
will likely run at a priority that exceeds the priorities of
all its clients. The scheduling method may be any of the
three previously described, but round-robin is probably the
most common.
If a low-priority client sends a message to the server, then
its request will by default be handled at the higher
priority of the server. This has indirectly boosted the
priority of the client, because the client's request is what
causes the server to run.
As long as the server runs for a short period of time to
satisfy the request, this usually isn't a concern. If the
server runs for a more extended period, then a low-priority
client may adversely affect other processes at priorities
higher than the client but lower than the server.
To solve this dilemma, a server may elect to have its
priority driven by the priority of the clients that send it
messages. When the server receives a message, its priority
will be set to that of the client. Note that only its
priority is changed — its scheduling method stays the
same. If another message arrives while the server is
running, the server's priority will be boosted if the new
client's priority is greater than the server's. In effect,
the new client “turbocharges” the server to its
priority, allowing it to finish the current request so it
can handle the new client's request. If this weren't done,
the new client would have its priority lowered as it blocked
on a lower-priority server.
If you select client-driven priorities for your server, you
should also request that messages be delivered in priority
order (as opposed to time order).
To enable client-driven priority, you use the
qnx_pflags() function as follows:
qnx_pflags(~0, _PPF_PRIORITY_FLOAT
| _PPF_PRIORITY_REC, 0, 0);
No matter how much we wish it were so, computers are not
infinitely fast. In a realtime system, it's absolutely
crucial that CPU cycles aren't unnecessarily spent. It's
also crucial that you minimize the time it takes from the
occurrence of an external event to the actual execution of
code within the program responsible for reacting to that
event. This time is referred to as latency.
Several forms of latency are encountered in a QNX system.
Interrupt latency is the time from the reception of
a hardware interrupt until the first instruction of a
software interrupt handler is executed. QNX leaves
interrupts fully enabled almost all the time, so that
interrupt latency is typically insignificant. But certain
critical sections of code do require that interrupts be
temporarily disabled. The maximum such disable time usually
defines the worst-case interrupt latency — in QNX this
is very small.
The following diagrams illustrate the case where a hardware
interrupt is processed by an established interrupt handler.
The interrupt handler either will simply return, or it will
return and cause a proxy to be triggered.
Interrupt handler simply terminates.
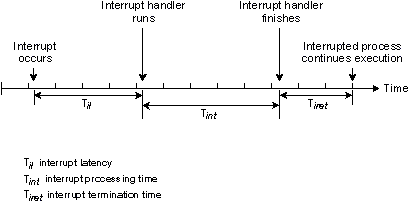
The interrupt latency (Til) in the
above diagram represents the minimum latency —
that which occurs when interrupts were fully enabled at the
time the interrupt occurred. Worst-case interrupt latency
will be this time plus the longest time in which
QNX, or the running QNX process, disables CPU interrupts.
The following table shows typical interrupt-latency times
(Til) for a range of processors:
| Interrupt latency (Til): | Processor: |
|---|
| 4.3 microsec | 133 MHz Pentium |
| 4.4 microsec | 100 MHz Pentium |
| 7 microsec | 100 MHz 486DX4 |
| 15 microsec | 33 MHz 386 |
In some cases, the low-level hardware interrupt handler must
schedule a higher-level process to run. In this scenario,
the interrupt handler will return and indicate that a proxy
is to be triggered. This introduces a second form of latency
— scheduling latency — which must be
accounted for.
Scheduling latency is the time between the termination of an
interrupt handler and the execution of the first instruction
of a driver process. This usually means the time it takes to
save the context of the currently executing process and
restore the context of the required driver process.
Although larger than interrupt latency, this time is also
kept small in a QNX system.
Interrupt handler terminates, triggering a proxy.
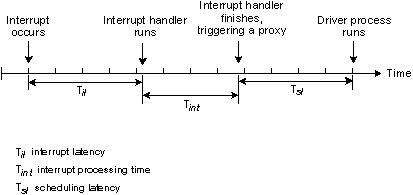
It's important to note that most interrupts
terminate without triggering a proxy. In a large number of
cases, the interrupt handler can take care of all
hardware-related issues. Triggering a proxy to kick a
higher-level driver process occurs only when a
significant event occurs. For example, the interrupt handler
for a serial device driver would feed one byte of data to
the hardware upon each received transmit interrupt, and
would trigger the higher-level process (Dev) only
when the output buffer is finally empty.
This table shows typical scheduling-latency times
(Tsl) for a range of processors:
| Scheduling latency (Tsl): | Processor: |
|---|
| 7.8 microsec | 133 MHz Pentium |
| 10.1 microsec | 100 MHz Pentium |
| 16 microsec | 100 MHz 486DX4 |
| 38 microsec | 33 MHz 386 |
Since microcomputer architectures allow hardware interrupts
to be given priorities, higher-priority interrupts can
preempt a lower-priority interrupt.
This mechanism is fully supported in QNX. The previous
scenarios describe the simplest — and most common
— situation where only one interrupt occurs.
Substantially similar timing is true for the
highest-priority interrupt. Worst-case timing considerations
for lower-priority interrupts must take into account the
time for all higher-priority interrupts to be processed,
since in QNX, a higher-priority interrupt will preempt a
lower-priority interrupt.
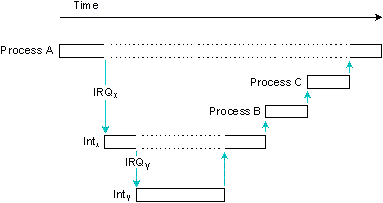
Process A is running. Interrupt IRQx causes
interrupt handler Intx to run, which is
preempted by IRQy and its handler
Inty. Inty triggers a proxy
causing Process B to run; Intx triggers a
proxy causing Process C to run.