Print Spooling
This chapter covers the following topics:
- Introduction
- Using the spool utilities
- Spooler architecture
- The spool setup file
- Using setup files
- Example setup files
- Accessing spoolers and queues
Introduction
Sharing resources on a network
QNX encourages the distribution of resources throughout a network with few artificial boundaries. Every device (disk, modem, printer, etc.) connected to a computer is, by default, a shared resource. Thus, a program running on any computer has equal access to any device on the network, whether the device is connected to the same computer (local) or to another machine (remote).
Although it's easy for a user to transparently access any resource on the network, the system administrator may need to take steps to control access to certain types of resources. Printers and modems, for example, can be used by only one user at a time (unlike hard disks, which can be accessed by many users concurrently) and therefore require some sort of enqueuing facility to avoid conflicts. To allow convenient access to these shared yet exclusive resources, QNX provides a set of spooling services.
Spoolers
A spooler is simply a mechanism that accepts requests for a resource and then allocates the use of the resource according to a set of specified rules.
To understand how a spooler can be useful, let's look at how it controls access to a printer. A printer must be available at all times to users, yet it can print only one job at a time. If a spooler is present, users can send their data through the spooler rather than directly to the printer. Upon receiving data destined for the printer, the spooler writes this data into a temporary file instead of sending it immediately to the printer. Later, when the printer becomes available, the spooler will write the data to the printer. Thus, many users can freely submit print jobs, even though only one physical printer exists.
QNX implements spooling through the use of named queues that are referenced by the “lp” set of utilities; these queues also exist in the file namespace in the /dev/spool directory. Data written to a queue will be placed on an internal list and ultimately sent to a defined output device.
The QNX spooling server (lpsrvr) can maintain many different spool queues. The following utilities operate on spool queues:
| lp | submit files to a spool queue |
| lprm | remove jobs from a spool queue |
| lpc | control spooler queue |
| lpq | display spool queue status |
For more information on these utilities, see the Utilities Reference. For information about how to queue print jobs to a printer on a TCP/IP network, see the lpd package included with TCP/IP for QNX.
Using the spool utilities
Starting the spooler
Before any spooling can occur in a QNX system, you must run lpsrvr:
lpsrvr &
To determine what resources it has available, and how it's expected to manage them, the lpsrvr utility first looks for a setup file called /etc/config/lpsrvr.node (where node is the node ID of the node lpsrvr is running on). If no setup file is found with a .node extension, lpsrvr will use the /etc/config/lpsrvr file, which is found on the standard QNX distribution disks.
Submitting spool jobs
The following lp command will cause the file report to be inserted into the default spool queue and ultimately printed:
lp report
For more information on the default queue, see “The spool setup file” section.
In systems where more than one spool queue is available, you can specify the queue name. The following command inserts report into a spool queue called txt:
lp -P txt report
You could also use a command that writes directly to the queue file:
cp report /dev/spool/txt
Querying spool jobs
To examine the spool queue, you can use the lpq utility. The following is a sample output from lpq:
1: steve [job #39] 1400 bytes lalist.doc 2: aboyd [job #42] 2312 bytes netdrvr.c
This utility lets you determine when any submitted jobs have been completed; it also provides the spool job ID for use with other lp utilities.
Canceling spool jobs
The lprm utility lets you remove jobs from a spool queue. You can remove a job explicitly by specifying its job ID number. Given the state of the default queue shown above, steve's job (#39) could be canceled with this command:
lprm 39
If job #39 is currently in progress, it will be abandoned. The success of abandoning current spool jobs may vary with the type of output device you're using — some printers have large internal buffers.
The superuser may also remove all jobs belonging to a particular user. For example, all of steve's jobs can be canceled with the following command:
lprm steve
Controlling the spool queues
The lpc utility is a system administration tool for managing spoolers. It lets you perform many control functions, such as starting up or shutting down a queue. The following basic functions are provided:
- suspend/resume enqueuing of jobs
- suspend/resume dequeuing of jobs
- suspend/resume the current job
- delete the current job
- rearrange the jobs in a queue
- move jobs to a different queue
- display the status of queues
Note that lpc's functionality overlaps that of lpq and lprm. This overlap is convenient, because unlike lpq and lprm, lpc can be used interactively.
Spooler architecture
The QNX spooling system is based on two objects: queues and targets. These work with each other to provide a flexible method of controlling data transformations and queuing.
A queue is an internal list of pending data to be sent to a target. As mentioned earlier, each queue is given a name that users specify when submitting jobs.
A target is associated with the physical output device (e.g. a printer) and removes jobs from queues. You can connect the output of a queue to one or more targets or connect multiple queues to a single target. However, you can connect the output of a target to only one device.
Queues can have optional attributes called filters, which are of two types:
- copy-in (ci) filters, which perform operations on the data before it's copied onto a queue (e.g. pagination)
- copy-out (co) filters, which operate on the data after it's removed from a queue.
Targets may have an optional control program (cp) that allows the output device to be initialized between jobs if required. For example, if a job were aborted and the device needed to be primed again, a device-specific control program could detect SIGTERM and take whatever action necessary to restore the device to a stable state.
The following diagrams illustrate how queues, filters, and targets can be configured to work with each other.
One queue feeding a single target
The following configuration could be used where there's a single printer and where a single (or no) translation of the data is required (e.g. a dot matrix printer):

Multiple queues feeding a single target
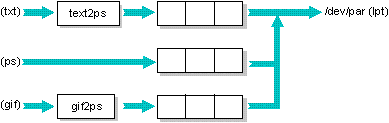
Multiple queues may feed a single target, in which case the target will select the appropriate job from all the jobs in those queues based upon queue priority, then upon time of submission (i.e. the oldest pending job).
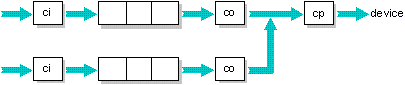
At the end of this chapter, you'll find several example setup files. The above configuration is used in the example file in which one queue converts ASCII to PostScript, while the other is a direct PostScript queue. Both queues feed the same target, which sends the data to the PostScript laser printer.
One queue feeding multiple targets
If the output of a queue is sent to many targets, the spooler will select whichever target is available. The following configuration is useful if you have three printers side by side and it doesn't matter which one prints your job.
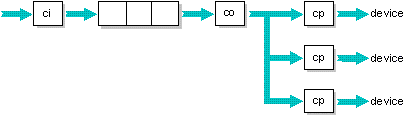
Multiple queues feeding multiple targets
The following configuration is a combination of the previous two examples. A third queue has a separate channel to one of the targets. This channel could be used to ensure that jobs requiring the third printer are always sent to that printer (e.g. the printer has color capabilities).
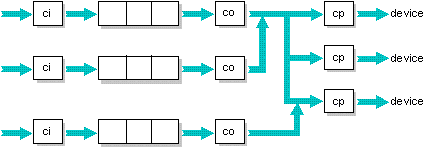
Chaining queues
The output of a queue is usually sent to one or more targets, but it's possible instead to chain the output into another queue.
With chaining, the output of a queue is placed directly onto the destination queue, thus avoiding any possible copy-in operation on that queue. If the final queue in a chain has a copy-out filter, the filter will be applied.
When started, the spooler accesses a file to get its
configuration information. If no file is specified on the
command line, the spooler uses the
/etc/config/lpsrvr file. This file defines
queues, targets, and the relationships between them.
Queues and targets have symbolic names as well as a set of attributes.
Each entry in the setup file has the following format:
The definition of a queue or target begins with a
[name] directive and consists of all valid
attribute specifications until the next [name]
directive. All leading white space is ignored. Comment lines start
with a pound sign (#).
If a single attribute spans two lines, the last character
before the Newline character must be a backslash
(\).
The name may be up to 48 characters long and may contain
only alphanumeric characters.
If the object being described is a target, the name must be
preceded by a dash (-). The dash is for delineation
only; it isn't considered part of the name.
Each attribute consists of a two-letter key in one of the
following forms:
All numbers are assumed to be decimal numbers,
unless they start with a leading zero (meaning octal) or a
leading 0x (meaning hex).
All strings contain printable characters. The backslash
(\) is a “special” character.
It can be used to escape other characters. For example, a
“real” backslash must be represented
with: \\
The following table describes all defined keys, including the default
used for each key if its corresponding attribute isn't specified. In
the Use column, “Q” means “queue,”
“T” means “target,” and “G” means
“global.”
Since the keys are case-sensitive, we reserve all keys
formed by two lowercase letters. You can safely implement
custom extensions by using uppercase or mixed-case keys. The
spooler utilities will ignore any options they don't
understand.
Two keywords, sp and cd, can define global
information for the spooler. To make them apply globally,
you precede these keywords with a pair of empty brackets
([ ]).
Since the spooler always adopts the
/dev/spool file namespace, only one spooler
may run on each node. You can run multiple spoolers on your
network if each spooler registers a different global name.
Otherwise, each spooler will attempt to register the same
default global name /qnx/spooler. With
multiple spoolers, you may wish to use names such as
/qnx/spooler2, /qnx/spooler3,
and so on.
To specify the global name to be registered by a spooler,
you use the sp command in the setup file. The
name must always begin with a leading slash (/). If
no sp keyword is specified, the default name
/qnx/spooler is globally registered (i.e.
network-wide).
The cd keyword lets you define the directory to
use for the creation of the spooler's temporary spool files.
By default, temporary files are created in the
/usr/spool/lp directory. These files get
deleted when they're no longer required.
Any path you specify to the cd keyword should
begin with a leading slash. Note that the specified
directory must exist, with appropriate access rights
assigned.
The following example setup file informs the spooler to
register the name /qnx/spooler2; it also
places temporary files in the /tmp/spool2
directory:
The spooler will set the following metavariables
appropriately when it encounters them:
In addition, all the keys defined above can be referenced as
metavariables. For example, $(ci) will expand to
the name of the copy-in command,
ci=string.
The cat command is used as the default copy-in
and copy-out filter commands. Also, unless otherwise
specified in the setup file, the standard input and standard
output of filter commands are automatically connected to
default files or processes. The default for copy-in is as
follows:
There are two possible defaults for a copy-out, depending on
whether or not a control program (i.e.
cp) is defined:
For example, a setup file like this:
would result in the following substitutions:
When you create a setup file, you specify each queue by
giving it a name and an optional list of parameters; you
specify each target by starting its name with a dash
(-). To illustrate, here's a very simple setup
file:
In this file we have a queue called txt and a target
called lpt. When data is sent to the txt
spool queue, the data is saved in a temporary spool file and is known
as a “job.” When the spooler removes that job from the queue,
the job is placed on the target, lpt, which then directs
the data to the parallel port, /dev/par.
It's often necessary to filter spooled data, so
lpsrvr provides the copy-in and
copy-out mechanisms. As mentioned earlier, copy-in
is run before the data is placed on the queue, while
copy-out is run after the data is removed from the queue.
Note that if you have many queues feeding a single target
and one of the queues has a copy-out filter that may take a
long time to run, the target will be temporarily unavailable
to the remaining queues if that queue is selected. (For more
information, see the “Example
setup files” section.)
A good example of the use of a copy-in filter is to pass the
data through pr to paginate it:
You might use a copy-out filter, for example, when you have
both a PostScript laser printer and an HP laser printer. You
could have two copy-out filters to generate the proper
output format. Let's say you have two programs:
txt2ps, which generates PostScript, and
txt2hpgl, which generates hpgl:
Queues can be chained — this moves the job from queue
to queue. The following is a simple example of chaining onto
a queue named tmp, which then sends the data to the
lpt target:
The af keyword lets you specify a filename that
the commands may access as $(af) so they can write
any information they want to log.
The invoking lp utility will report any errors
that occur during the input of data into a queue. If you
submit data by directly writing to the spool file in the
/dev/spool directory, write errors will occur
if something prevents a successful copy into the queue.
You can use the ab keyword to specify a command
to execute if a target abandons a job. The following would
inform the invoking user of the error via a mail message:
The following example shows a set of queues that share a
common target. The three queues are named:
The configuration is as follows:
Here's the file to set this up:
In this example, users send files with the lp
utility to the appropriate queue, which converts the file
through a copy-in filter (except for the ps
queue). The queue then sends the converted data to the
target, /dev/par.
Since the hypothetical filter programs text2ps
and gif2ps may take a relatively long time to
process a job, copy-in filters are used rather than copy-out
filters. A copy-out filter will tie up the target,
preventing other jobs from being dequeued while the filter
is running. The chosen configuration allows other jobs to be
sent to the target while the PostScript translation is being
generated.
Also, since GIF files tend to be large, they're assigned a
lower priority than the others.
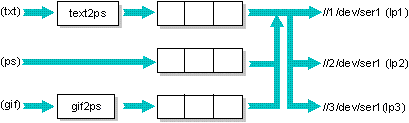
The following example is a further refinement of the above
setup, with some additional features required for a larger
configuration. There are now three laser printers, all
PostScript, located in different parts of the building
(connected to //1/dev/ser1,
//2/dev/ser1, and
//3/dev/ser1). The configuration looks like
this:
Here's the file to set this up:
The above configuration uses the same three queues described
earlier (txt, ps, and gif) but
they now feed three separate targets. The spooler selects
the first available target from the set of targets
(lp1, lp2, lp3) and sends the
data to its corresponding printer.
Queue selection is based on priority first, then on the age
of the job.
In this example, a mail message is sent to the submitter
indicating whether or not the job completed normally.
Many spoolers may be present on a network; each of these can
maintain multiple queues. To communicate with any given
spooler, the lp utilities first locate the
spooler through the unique global name that the spooler
registers (see the “Global keywords” section).
When using any lp utility, you can specify a
spooler and queue in several ways. You can:
If you don't specify the spooler on the command line, the
utility checks the LPSRVR environment
variable, which contains the name of the default spooler.
However, if LPSRVR isn't defined, the utility
will use the spooler that has registered the default global
name /qnx/spooler.
If the utility successfully locates a spooler, but you
haven't specified a queue on the command line, the utility
will check the LPDEST environment variable,
which contains the name of the default queue. However, if
LPDEST isn't defined, the utility will use
the first queue entry in the setup file of the located
spooler.
The LPSRVR and LPDEST
environment variables are used when the command-line
information given to the lp utilities doesn't
fully specify which spooler or queue to use.
LPSRVR specifies the default spooler. The
following setting of LPSRVR would indicate
that the default spooler is the one with the name
/qnx/spooler2:
The name specified in LPSRVR must always
begin with a leading slash. LPSRVR must never
contain the name of a queue.
LPDEST specifies the default queue. You can
use LPDEST in two ways. You can specify a
queue only:
Or you can specify a spooler and a queue:
If you specify a spooler in LPDEST, the
LPSRVR variable is ignored, even if it's
defined.
Let's look at a few simple examples that show some of the
ways you can specify spoolers and queues. For these
examples, let's assume you have two spoolers on the network,
each with two queues.
The first spooler uses the default global name,
/qnx/spooler; its queues are named
txt and ps. The second spooler uses the
name /qnx/spooler2; its queues are named
checks and waybills.
Let's say you enter the following lp command,
specifying neither a spooler nor a queue:
The utility will first try to locate a spooler by checking
LPSRVR. If that variable isn't defined, the
utility will locate the spooler with the default global
name /qnx/spooler.
The utility will then try to determine the queue by checking
LPDEST. If that variable isn't defined, the
utility will select the first queue specified in the setup
file of the located spooler.
If you specify a string that begins with a leading slash,
the string is always assumed to be a spooler name. Thus, if
you enter the following command, the utility will treat
/qnx/spooler2 as a spooler:
Because the second spooler uses /qnx/spooler2
as its name, that spooler will be located. The utility will
then try to use LPDEST as the default queue.
If LPDEST isn't defined, the job is submitted
to the queue checks, since that's the first queue
in the setup file of /qnx/spooler2.
If you specify a string that doesn't begin with a
leading slash, the string is always assumed to be a queue
name. Thus, if you enter the following command, the utility
will treat txt as a queue:
The utility will first try to locate a spooler by checking
LPSRVR. If that variable isn't defined, the
utility will use the first spooler, since that spooler has
registered the default global name,
/qnx/spooler.
In the following example, both the spooler and the queue are
named. Since the string begins with a leading slash, the
utility will initially attempt to find a spooler called
/qnx/spooler2/waybills.
However, since the spooler
/qnx/spooler2/waybills doesn't exist, the
search will fail, at which point the utility will treat the
specified string as a spooler name followed by a queue name.
The spooler with the name /qnx/spooler2 will
be located, and jobs will be submitted to the
waybills queue on that spooler.
You might find it useful to configure several default
spoolers, if, for example, your marketing, sales, and
R&D departments each has a spooler running:
LPSRVR=/qnx/spooler (marketing) You normally initialize environment variables beforehand in
system initialization files. You may wish to use one of the
following files to initialize the variables:
/etc/config/sysinit.node (run at boot time)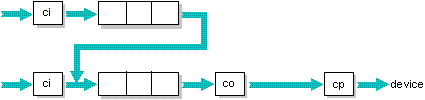
The spool setup file
Syntax definitions
[name]
attribute
attribute
.
.
.
Key: Description: Default: Use: ab=string Executed when target abandons command for any
reason nil; no command is executed T af=string accounting file that commands may use accounting isn't performed (lpsrvr logging is unaffected) Q cd=string directory where temporary spool files are found /usr/spool/lp G ci=string copy-in command; used before placing
the job on the queue binary copy-in of job; no transformation applied Q co=string copy-out command; used when
removing job from queue binary copy-out of job; no transformation applied Q cp=string device control program; used by the
target binary copy of job; no transformation applied T dv=string device that the target uses output is sent to standard output of lpsrvr Q, T mn#numeric minimum number of jobs for queue
before flushing 0; jobs are despooled ASAP Q mx#numeric maximum number of jobs the queue will hold no limit; queue limits are based on memory and disk space Q na=string name; a string that describes the queue or target nil string Q, T ok=string command executed when target completes normally nil; no action is performed T pr#numeric priority to run this queue at (1-100); 100 is the highest 50 Q qn=string queue to chain a despooled job onto nil; delete job after despooling Q re#numeric retries when a job fails 0 Q rt#numeric retry time; number of seconds or die forever Q sp=string registered name of spooler maintaining this queue /qnx/spooler; registered only if no queue specifies a name G ta=string target to be associated with this queue output is sent to standard output of lpsrvr Q wa#numeric wait this number of seconds before despooling each job 0; jobs are despooled ASAP Q Global keywords
Registering names — sp
Specifying a temporary directory for spool
files — cd
# Global spooler variables
[ ]
sp=/qnx/spooler2
cd=/tmp/spool2
# Text queue
[txt]....
Metavariables
Variable: Description: $(file) the filename of the submitted file or
“--standard input--” if no name is provided $(fname) the fully resolved pathname of the submitted file or
“--standard input--” if no
name is provided $(spfile) the name of the spool data file $(username) the login name of the user who submitted the job $(userid) the numeric user ID of the user who submitted the job $(queue) the name of the queue the job currently belongs to $(target) the name of the target the job currently belongs to $(device) the name of the device the job is scheduled on $(ncopies) the number of copies the user requested $(jobid) the job ID number of this job $(cifile) a temporary name that copy-in routines may use Default behavior
cat < $(fname) > $(spfile)
cat < $(spfile) > $(device)
cat < $(spfile) | $(cp) > $(device)
[txt]
ta=lpt
ci=pr -f -h
co=txt2ps
cp=init_printer
[-lpt]
dv=/dev/par
pr -f -h < $(fname) > $(spfile)
txt2ps < $(spfile) | init_printer > /dev/par
Using setup files
Queues and targets
[txt]
ta=lpt
[-lpt]
dv=/dev/par
Filters
Using copy-in
[txt]
ci=pr -f -h "$(file)"
ta=lpt
[-lpt]
dv=/dev/par
Using copy-out
[ps]
ta=lpt1
co=txt2ps
[hp]
ta=lpt2
co=txt2hpgl
[-lpt1]
dv=/dev/ser
[-lpt2]
dv=/dev/par
Chaining queues
[txt]
qn=tmp
[tmp]
ta=lpt
[-lpt]
dv=/dev/par
Accounting information
Input errors
Output errors
ab=echo lpsrvr print job $(jobid), file $(file) failed \
| mailx $(username)
Example setup files
Multiple queues feeding a single target
# ASCII to postscript queue:
[txt]
ta=lpt
ci=text2ps
pr#50
# direct postscript queue:
[ps]
ta=lpt
pr#60
# GIF to postscript queue:
[gif]
ta=lpt
ci=gif2ps
pr#5
# target printer:
[-lpt]
dv=/dev/par
Multiple queues feeding three targets
# ASCII to postscript queue:
[txt]
ta=lp1,lp2,lp3
ci=text2ps
pr#50
# direct postscript queue:
[ps]
ta=lp1,lp2,lp3
pr#60
# GIF to postscript queue:
[gif]
ta=lp1,lp2,lp3
ci=gif2ps
pr#5
# target printers:
[-lp1]
dv=//1/dev/ser1
ok=echo file $(fname) sent to $(target) \
| mailx $(username)
ab=echo file $(fname) did not get printed \
| mailx $(username)
[-lp2]
dv=//2/dev/ser1
ok=echo file $(fname) sent to $(target) \
| mailx $(username)
ab=echo file $(fname) did not get printed \
| mailx $(username)
[-lp3]
dv=//3/dev/ser1
ok=echo file $(fname) sent to $(target) \
| mailx $(username)
ab=echo file $(fname) did not get printed \
| mailx $(username)
Accessing spoolers and queues
LPSRVR and LPDEST
LPSRVR
export LPSRVR=/qnx/spooler2
LPDEST
export LPDEST=waybills

Examples
First spooler: Second spooler: /qnx/spooler/txt /qnx/spooler2/checks /qnx/spooler/ps /qnx/spooler2/waybills Naming neither a spooler nor a queue
lp test.dat
Naming only the spooler
lp -P /qnx/spooler2 test.dat
Naming only the queue
lp -P txt test.dat
Naming both the spooler and the queue
lp -P /qnx/spooler2/waybills test.dat
Initialization files
LPSRVR=/qnx/spooler2 (sales)
LPSRVR=/qnx/spooler3 (R&D)
/etc/default/login (run at login time)
/etc/profile (run by every login Shell)